What Is Agentic RAG? A Plain-English Explainer
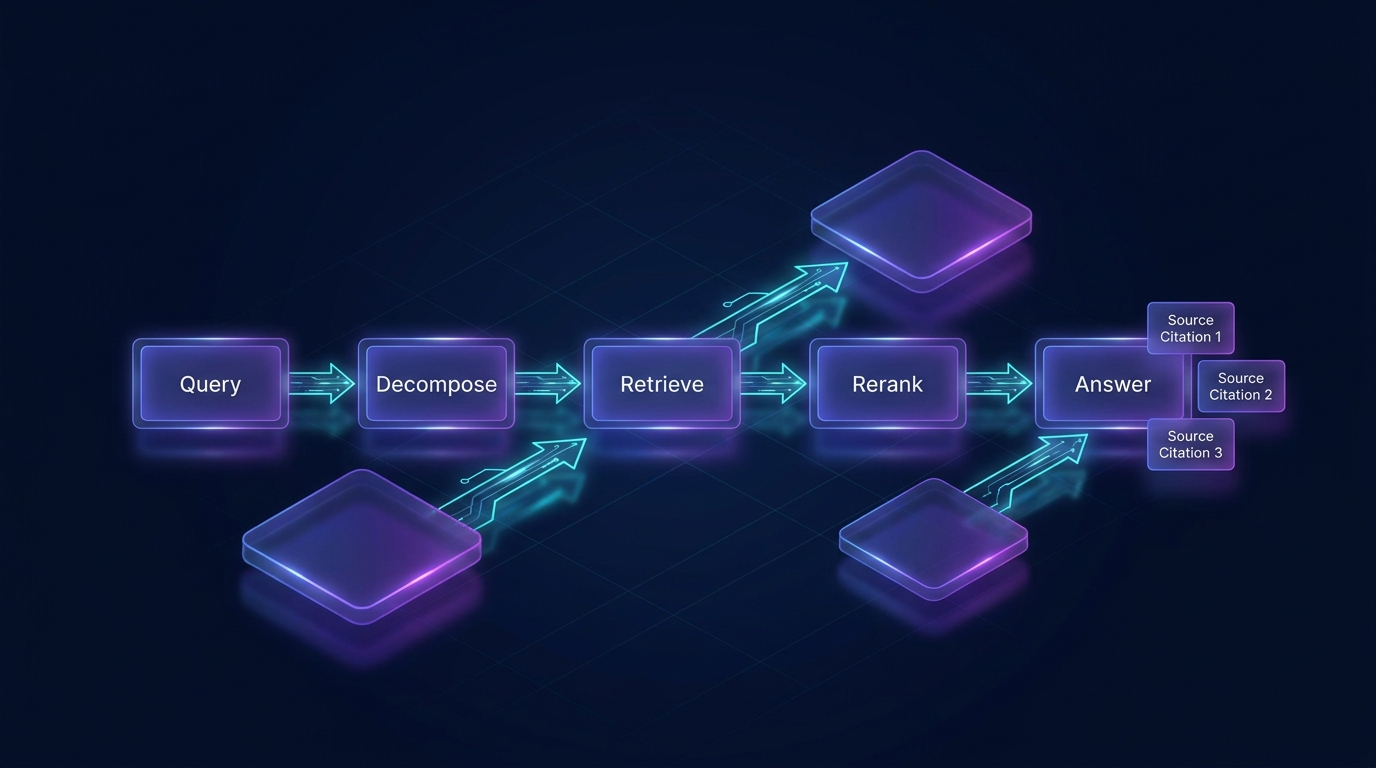
If you have used a modern "chat with your documents" tool, you have used RAG — even if nobody told you what it was called.
RAG stands for Retrieval-Augmented Generation. It is the technique that lets an AI answer questions about documents it was not trained on. Agentic RAG is an evolution of that technique that produces noticeably better answers for complex questions.
This post explains both, without requiring any AI background.
The problem RAG solves
Language models like Gemma 4 are trained on large amounts of text, but that training has a cutoff date and does not include your documents. You cannot ask a base language model "What does clause 12 of my contract say?" because it has never seen your contract.
The naive solution is to paste the entire document into the model's context. This works for short documents but fails for anything longer — models have context limits, and stuffing a large document into the prompt produces slow, expensive, and often inaccurate responses.
RAG solves this by retrieving only the relevant parts of your document before generation.
How basic RAG works
- Chunk: split the document into segments (paragraphs, sections)
- Embed: convert each chunk into a vector — a mathematical representation of its meaning
- Store: save all vectors in an index alongside the original text
- Query: when you ask a question, embed the question and find the chunks with the most similar vectors
- Generate: pass those chunks and your question to the language model and generate an answer
This works well for simple, direct questions. "What is the refund policy?" → retrieve the refund section → generate an answer. Clean.
The limitation is step 4. Vector similarity (dense retrieval) can miss chunks that are relevant but use different words to your question. It also struggles with complex questions that require pulling information from multiple parts of a document.
What agentic RAG adds
Agentic RAG treats the retrieval process as an active, multi-step reasoning task rather than a single lookup. The key additions are:
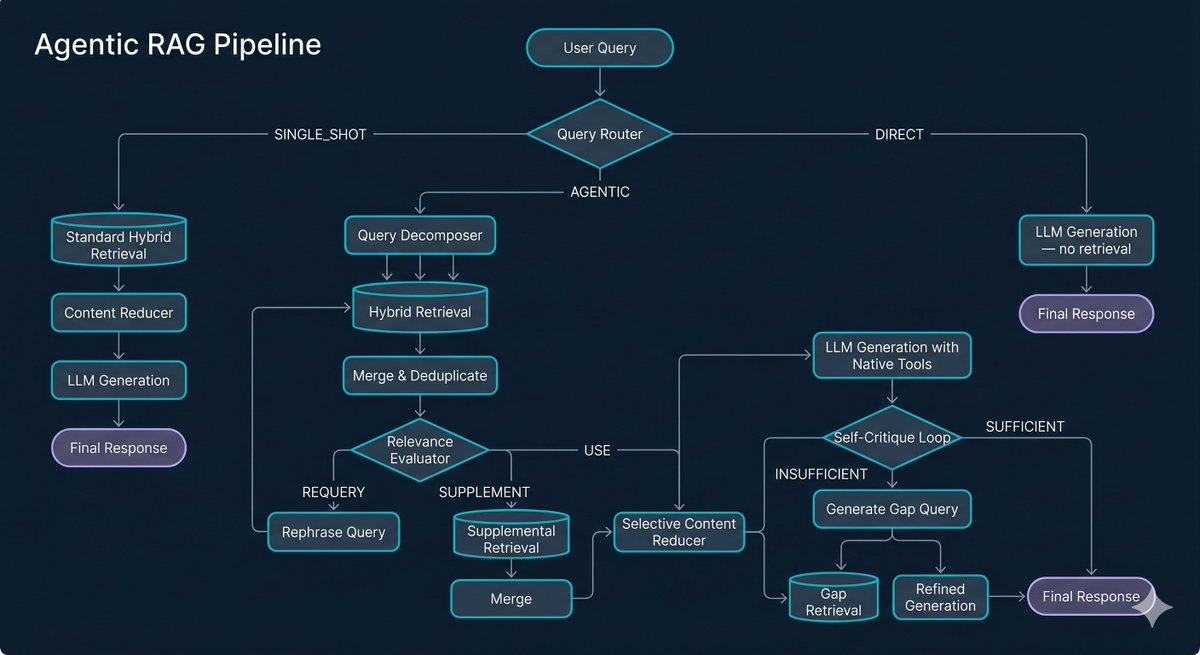
Query routing
Before retrieving anything, the system analyses your question and decides how to handle it. Simple factual questions go through a fast direct retrieval path. Complex, multi-part questions are routed to the full agentic pipeline.
Query decomposition
For complex queries, the system decomposes your question into sub-queries and runs retrieval independently for each. If you ask "Summarise the risks in the executive summary and explain how the mitigation plan in section 4 addresses each one" — that is two separate retrieval tasks. A simple RAG system tries to answer with one retrieval pass and usually fails. An agentic system handles each part separately and synthesises the results.
Hybrid search
Rather than relying only on vector similarity, the retrieval combines two methods:
- Dense retrieval: finds chunks with similar meaning to your question
- Lexical search: finds chunks that contain the same keywords as your question
Both produce ranked candidate lists. Reciprocal Rank Fusion (RRF) merges them into a single ranking. The weight between the two methods shifts dynamically — queries about tables or numbers lean more toward lexical matching, while conceptual questions lean more toward vector similarity.
Corrective RAG (CRAG)
Before generating an answer, the system evaluates whether the retrieved chunks actually contain useful information. Three outcomes are possible:
- Use: the chunks are relevant — proceed to generation
- Requery: the chunks are not relevant — rephrase the query and retrieve again (up to two rephrase attempts)
- Supplement: the chunks are partially useful — fetch additional chunks and merge them in
This corrective step significantly reduces cases where the model invents an answer because its retrieved context was incomplete.
Self-critique
After an answer is generated, the system checks whether it is actually sufficient. If it detects gaps — for example, the answer referenced a section that was not fully retrieved — it generates a targeted follow-up query, retrieves the missing context, and re-generates a more complete answer.
Native tool calling
During generation, the model can autonomously call retrieval tools mid-response. If Gemma 4 determines while writing its answer that it needs a specific section it does not have in context, it can call searchDocuments() or getDocumentSection() to fetch it on the fly. This allows the model to be genuinely self-directed rather than limited to the context it was initially given.
How Anvit implements this on-device
Anvit runs a full agentic RAG pipeline entirely on your Android phone:
- Chunking: documents are split into section-aware chunks, preserving the heading hierarchy. Tables are kept as intact structured units. Each chunk knows which section it came from.
- Embedding: EmbeddingGemma or Gecko runs on-device via MediaPipe.
- Hybrid retrieval: dense vector search plus lexical full-text search, fused with RRF.
- Corrective RAG: a three-action relevance evaluator (USE / REQUERY / SUPPLEMENT) runs before every generation.
- Self-critique: post-generation gap detection with automatic refinement.
- Tool calling: Gemma 4 can call search tools autonomously during generation.
- Sources panel: every response shows which document sections were used, so you can verify the answer against the original content.
Everything runs locally. No query, no document content, and no intermediate reasoning step leaves your device.
When does it actually matter?
Simple factual questions ("What is the deadline?", "Who is the counterparty?") work fine with basic RAG. For these, the agentic pipeline runs fast and the extra steps are invisible.
The difference shows up for:
- Multi-part questions: anything requiring synthesis from different sections
- Analytical questions: comparing, summarising, or evaluating information
- Questions with ambiguous scope: where the relevant passage is not obvious from keywords alone
- Long documents: where the relevant content could be anywhere in a large file
Think Mode in Anvit surfaces the reasoning steps, so you can see exactly how the model approached a complex question.
RAG went from a research concept to the standard architecture for document AI in a few years. Agentic RAG — with corrective retrieval, self-critique, and tool calling — is the current best practice. Running it on-device removes the last reason to send your documents to the cloud. Try it on Android.